学用Eleventy(一):路由
Eleventy是什么
Eleventy(下称11ty)是node平台最时髦的 静态网站生成器(Web site generator)之一。如果你用过 ruby平台的Jeklly ,或者 hexo 创建过静态博客,一定明白 11ty 是什么。如果没有(只开发过数据库驱动的动态网站),了解一下 什么叫 静态型网站 就明白了。
静态型网站
现代网站有很多种形态,最常见类型有电商,社交,论坛和工具(像搜索引擎),但不能忘记还有原初的传统的网站形态。这种原始网站类型的功能是较简单的,页面是静态不怎么变化的。这种传统网站类型其实依然有很大的市场需求,例如用于企业营销,个人博客,和公司产品宣传册等。
静态网站功能可大可小,但无论功能如何,一般不手工制作,我们需要工具。开发网站我们一般使用框架,例如 ASP.NET, PHP Laravel,Node express等。对于静态网站来说,这些都是牛刀。Jeklly,11ty 等就是设计用来开发静态网站的 网站生成器。
网站生成器
了解了静态网站的本质和需求,也要认识一下网站生成的原理。静态网站可大可小,共同的特点都由一系列静态页面构成,这些页面1)可以构成会话,或业务关系,2)页面有结构,3)也会有一些共通的数据,所以在制作时 可通过 数据 集中 生成这些页面,所以 叫生成器。
网站生成器,和我们一般开发者认知的 应用框架 其实 只是 工具的功能大小,和针对项目类型(主要是架构类型)不同而已,例如网生只适用于开发静态渲染的网站。网生和框架 本质是类似的,都是用来开发 某种架构的网站 的大型开发工具 。
网站架构
网站是一种基于http的分布式系统,大型的网站的架构是很复杂的,开发它也就变得复杂。静态型网站的构架是最简单的,但它只是特例,类型不全面。网站架构主要由路由,页面和渲染方式组成,静态网站几乎感觉不到路由器的存在,页面渲染也只是直接响应用户的http 请求。网站架构的话题比较大,有机会介绍全能应用框架(例如next remix)再说。
生成器与应用框架
由上可得,静态型网站除了页面结构相对稳定,功能较单一,它的架构也是有自己的特点,11ty 就是针对开发此类架构特点的网站的便利工具。
11ty 由于针对于网站类型属于小型,小规模的,所以11ty被定义为 网站生成器,而不是常见的应用框架。然,这两者界限不是特别清楚。有一种看法是,应用框架是集成保证网站商业品质 的一系列工具和资源,包括:
- 第一,提高开发效率,网站性能和开发者的开发体验的工具
- 第二,有丰富成熟的社区和生态
从这个界定上看,11ty 的确不像 gatsby , next那的全面。11ty 主打特点 就是灵活,包前端框架独立,模板引擎独立,你可选择你喜欢的前端库,模板引擎 开发和扩展,11ty社区主背靠node社区。
11ty
11ty 继承了流行生成器的所有优点和便利性(几乎复制了Jeklly的特性),并有所创新,具体如何便利,我们以分析一个 使用11ty开发的博客为例。
本教程以系列完成,并且不从头介始如何使用11ty,主要以介绍如何 使用11ty 工具特性 开发 网站常规架构块(building block),包括 路由,渲染和页面交互等。故,假设读者 至少有过 web开发经验,不限于node 平台的经验。
路由是什么
在开始分析博客源码前,先介绍网站架构最重的建构块——路由。
当我们拿一个新项目需求,或者项目源码要阅读,应该从哪里着手,着手设计和分析呢?很多人会不自觉的从具体的交互功能,和具体模块源码分析开始,因为那很直观。然而,更有效的方式 其实是从路由着手,只是路由比较抽象的,对生手不友好。
网站程序作一种GUI应用 是一定有路由的,因为路由是指 页面的路由——页面的切换,有用的应用很少只有一个页面,大型应用路由很复杂。
路由程序的构成
不是所有网站类型 有明显 路由模块,它们一定有页面,但不一定很具体有一个路由模块,像React Router这种库,或者express有一个router对象。
想像一下一个网站,有一个 ==产品列表==(product-list)页,点某个产品可看 ==产品的详细==(product?id=123),这个产品详细页(product)有一个返回主面的链接。
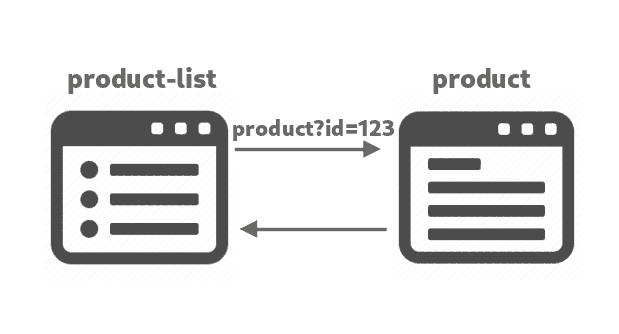
从这个最简单的例子可看 路由程序 的组成。
网站路由功能主要由一个 路由模块实现,且有相关的一些数据结构,和概念组成。
- ==路由项==就是被加载的页面,例如上面的产品列表页(product-list)和产品明细页(product?id=123);页面的URL地址就是==路由项==。一些集中式路由,还会有由多个表项组成 ==路由表== 数据结构;
- ==路由器==负责监测用户的路由请求(http页面请求),查询路由表,再执行页面加载
简单的网站,例如静态型的,路由任务比较简单——文件名就是路由项,路由模块集成在http server上去了;但对复杂的网站,可能需更强更复杂的路由功能,例如1)路由有参数需要处理,2)对路由请求的访问授权,3)将路由功能移到前端等功能等等,这需要一个独立的路由模块负责。
网站常见路由功能主要有以下一些:
- 静态路由:一般是简单的静态页面
- 逻辑路由:为页面定义一个新名(路由表项),如博客文章有一个富语义的url地址
- 动态路由或函数路由:页面加载需参数,例如产品明细页需要一个产品id
- 嵌套路由:这个比较复杂,将页面的布局信息提取出来,高级框架才有这个功能,像remix,next也有了
- 自由路由:一般页面只有交互功能,带导航跳转(通过 link交互)的叫自由路由
- 编程路由:像redirect 那通过代码 实现路由转向
- 特殊路由:像 页面访问授权 那样 给路由处理添加特殊业务逻辑
以上是网站 页面路由 小理论,并不算全面(有待完善)。下面开始分析项目代码。
博客网站
我们准备以分析11ty官方提供的博客模板(eleventy-base-blog)为例子,不过开始之前先介绍一下常规博客网站的功能。
博客属于内容管理(CMS)的一种,它可以做成动态的,因为博主要发布新文章和编辑页面内容,例如 wordpress 就是专业制作动态博客。但是如果博客更新比较慢(常常都是),做成静态也是比较合理的。
博客的网站功能可大可小的,如果用过wordpress就知道 有大量插件可用就理解了,不过博客核心功能主要是围绕 博文(post)的展示和整理,例如 打tag和 分类归档等。
博客种类
按照功能丰富程度分类,博客可分为
- 简单博客:无评论和搜索功能,静态生成
- 标准博客:如以jamstack 架构实现 评论和搜索,本地数据生成
- 传统博客:集成中后台界面和数据库
我将要分析的 eleventy-base-blog,它属于第一种,并且更简单一点,后面会介绍。
博客页面组成模式
任何站点都 是由一集 页面组成的,这些页面的功能 有很多种类,和复杂度,博客类站点 有一定的 页面组成模式,和固定的业务数据,例如:blog post tag page category 等,博客网站常见有以下的模块和功能:
- index 首页:时间倒序的 post 分页列表
- category:post 分页列表,按大类过滤
- tag : post 分页列表,按标签过滤
- archie 归档:post 分级列表,按日期 (年月)分组
- post :post 明细页
- page :page 明细页, page是特殊的post ,page列表通常以 导航菜单项 显示在 公共导航栏上
- search:post 分页列表,按关键词过滤
eleventy-base-blog
此博客模板只实现了 index tag archie post page 五个模块,具体路由表如下:
/
/tags
/tags/$tag-name
/posts
/posts/$post-name
/about此路由表中,有1)静态路由 和 2)动态路由,还有一个,3)逻辑路由(从源码可以看到 模块文件名和路由名不同)。接着来看看11ty的 网站路由开发技术 如何实现这个路由 的。
11ty的路由技术
这里重点提醒,页面路由和渲染是相互协作的两个任务,但它们的职责有时候比较模糊,区别主要在,路由的任务是围绕着路由表的;渲染的任务围绕着 页面结构和状态数据的。
好,我们先看eleventy-base-blog项目源码组成概况(精简路由相关的内容):
[radar@fedora eleventy-base-blog]$ tree --gitignore
.
├── _site
├── 404.md
├── about
│ └── index.md
├── archive.njk
├── _includes
├── index.njk
├── posts
│ ├── firstpost.md
│ ├── posts.json
│ ├── secondpost.md
├── tags-list.njk
└── tags.njk
1 文件目录即是路由表
11ty支持File-System Routing,这是现在很多新进的框架(像gatsby next remix)都支持的路由技术注 。这种路由表定义方式的确对开发者很友好,非常的直观。
11ty路由技术主要有以下几条规则:
第一,所有 页面模板 (包括有目录的)和路由项一对一,11ty支持多种模板引擎格式(这里有njk 和 数据内容模板 md);
第二,带下划线的(_)是中间处理数据,和不相关数据(如 _site),例如位于 _include目录里的布局layout模板,不会生成独立的页面;
第三,默认根目录就是路由目录,当然 为了清晰也可放进一个src目录,编译时再指定;
2 静态路由
文件路经就是 route值。静态是指页面文件 ==在路由处理时== 不作任何处理,不是页面内容静态不变,页面内容是 渲染的任务。base-blog有以下静态路由:
| 1 | 页面 | 模块文件 | 路由名 |
|---|---|---|---|
| 2 | 首页 | /index.njk | / |
| 3 | 关于 | /about/index.md | /about |
| 4 | 404 | /404.md | /404 |
3 逻辑路由
有时候我们想隐藏实现细节,让用户看到一个友好的路由名,例如给博文一个别名。这是最简单的 ==路由处理== 任务了。
| 1 | 页面 | 模块文件 | 路由名 |
|---|---|---|---|
| 2 | 存档 | /archive.njk | /posts |
| 3 | 所有tags | /tags-list.njk | /tags |
要改写页面模板的route值,要通过 模板 front matter 的 permalink 属性。例如 /archive.njk:
---
layout: layouts/home.njk
permalink: /posts/
---4 动态路由
路由本身就是一种以页面为单元分割程序功能的技术,所以==路由和页面==常常可以概念互换。而应用程序常常有一组相似的页面,可抽象出一通用页面模板,再用特定的数据派生多个具体的页面,有点像函数参数派生具体函数,这就是动态路由,其实也可叫==函数路由==。函数路由不负页面动态内容(那是渲染的职责),只负责 ==路由处理==中的参数处理——给页面模板传参数,再具体(由渲染器)渲染出不同的页面。
base-blog 有两个函数路由:
| 1 | 页面 | 模块文件 | 路由名 |
|---|---|---|---|
| 2 | 某篇文章 | /posts/[post-slug].md | /posts/[post-slug] |
| 3 | 某个tag的所有文章 | /tags | /tags/[tag] |
第一个函数路由(2 某篇文章),是一种二级结构(列表明细)的页面分割,有点像菜单,点击条目(route)将内容在新页面上展开;
第二个(3 某个tag的所有文章 ),是一种搜索结果集的页面分割,tag是搜索关键字;
搜索结果集常要分页,有分页的函数路由页面(base-blog没有实现,postslist.njk这个模板没有实现分页)会有多个关键字(其中一个是页码);
一项工具的设计 会想方设法针对最复杂的任务 作出优化,多个参数的函数路由是复杂的页面路由任务,11ty 的路由技术 有data cascade、 collection和 pagination 等函数路由优化技术。其中,数据源层叠 data cascade 是 11ty技巧的重心,渲染技术大量基于这个工具,路由也有。
参考此篇和文档。
5 编程路由和特殊路由
此两类路由功能需要用户参与,例如用户登录,属于运行时路由(相对于上面几种属于构建时路由),11ty 不支持,以及base-blog也 没有这个功能需求。
路由、页面 和渲染
网站 是由一集交互功能组成的,当交互功能增多并且变得丰富后,需要一个独立的路由程序 将交互功能分组,并且提供导航跳转,这是页面路由器最基本逻辑。这里我们必须注意将 路由、页面渲染,和交互区分开来。
掌握了网站的路由(功能种类,和路由表),对网站的功能就能有宏观的把握,接下来就可以纵向的展开,开发 每个路由项(页面)的具体功能。它就是 渲染,和交互。
- 不同的网站有不同的具体路由器实例,使用了框架或生成器,这个路由器实例是开发者在框架路由API之定制出来的。所谓路由技术是指,框架或生成器提供的路由定制API。例如文件系统式路由表,路由器是从文件系统中读出路由项信息,再执行路由操作。开发者在开发路由器实例需要做什么,取决于路由需求,和框架提供的API。↩